
This healthcare clearinghouse data primer will show how document processing tackles one of healthcare’s most time-consuming and vital components of revenue cycle management: EOB and claims processing.
What is a Healthcare Clearinghouse?
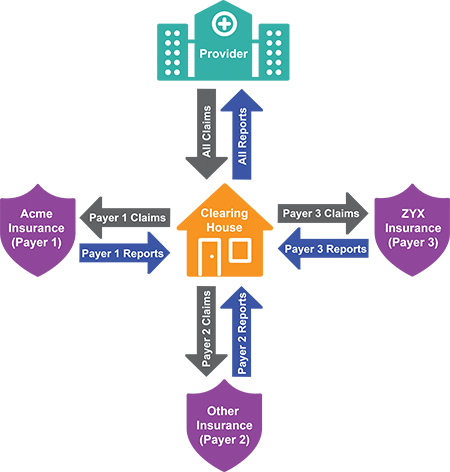 A healthcare clearing house (or medical claims clearinghouse) is a third-party company that processes claim information between provider entities (health clinics, doctor or dentist office, etc.) and insurance payers (insurance companies). The Department of Health and Human Services (HHS) says that health care clearing houses are a "public or private entity, including a billing service, repricing company, or community health information system"
A healthcare clearing house (or medical claims clearinghouse) is a third-party company that processes claim information between provider entities (health clinics, doctor or dentist office, etc.) and insurance payers (insurance companies). The Department of Health and Human Services (HHS) says that health care clearing houses are a "public or private entity, including a billing service, repricing company, or community health information system"
Basically, a healthcare clearinghouse checks over medical claims for errors or mistakes to make sure the claims can be accurately processed by the payer. Once accurate claims are received, the clearinghouse electronically sends either an acceptance or denial back to the healthcare provider.
Clearinghouses also have the ability to receive different formats of data and normalize them into one standard format that can then be integrated into the payer's adjudication management system.
Whether you are a healthcare clearinghouse company updating legacy software, or tasked with discovering a modern solution for integrating healthcare and payment transactions, this primer was designed for you.
Why Use a Health Care Clearinghouse?
Healthcare providers maintain focus on improving patient outcomes while navigating the stranglehold of bureaucracy, policy, rules, and compliance by using a healthcare clearinghouse for EOB and claims processing.
 Because healthcare data integration is the crux of revenue cycle management, workflows and processes must be optimized.
Because healthcare data integration is the crux of revenue cycle management, workflows and processes must be optimized.
With operating earnings on the decline and income erosion amounting to billions of dollars, the pressure is on for healthcare Providers to achieve sustained net operating margin.
How Can Clearinghouses Solve their Problems Easier
One of the best ways healthcare clearinghouse companies improve billing processes is through intelligent document processing. With thousands of different document types all conveying a limited amount of information, this is low-hanging fruit for automation.
Healthcare systems are feeling increasing pressure to adopt working value-based care models. And the best thing a healthcare organization can do to improve revenue cycle management is automating the integration of transactional data (both paper-based and electronic) between Payers and Providers.
Provider CIOs must discover new ways of optimizing the data and administrative processes necessary for future value-based payment arrangements.

Table of Contents:
- The Reality of Healthcare Data Integration
- Data Integration from Physical and Electronic Documents
- EOB Data Extraction
- How to Quickly Process Thousands of EOB Formats
The Reality of Data Integration for Healthcare Clearinghouse Companies
There is an immense amount of document and data formats used in healthcare. And it is not just different types of electronic forms.
Anyone not intimately acquainted with healthcare revenue cycle management might assume it is possible to simply purchase an EOB and claims processing solution and “just put it to work.”
The reality is that immense coordination is absolutely required between people, processes, and data.
When you break EOBs and claims down by document type you will quickly discover real-world challenges for processing and integrating the data.
Here are the most common documents and forms required for healthcare data integration:
- Explanation of Benefits
- EDI 835 File
- EDI 837
- CMS-1500
- UB-04
- Statement of Electronic Payment
- Correspondence
- Lockbox Information Files
- Patient Information Files
Explanation of Benefits
Explanation of Benefits (EOBs) are statements sent by a health insurance company to Covered Individuals and Providers explaining what medical treatments and/or services were paid (or not) on behalf of the patient. An EOB is commonly attached to a check or statement of electronic payment.
 EOBs sent to Providers contain information for multiple patients. They are sent both electronically in an electronic layout (called an ERA – Electronic Remittance Advice) that follows the EDI 835 standard (more on that later) or believe it or not, still on paper.
EOBs sent to Providers contain information for multiple patients. They are sent both electronically in an electronic layout (called an ERA – Electronic Remittance Advice) that follows the EDI 835 standard (more on that later) or believe it or not, still on paper.
Paper EOBs
Because EOBs often contain payment documents, they are generally processed by a bank lockbox processing service. The Provider will have a PO Box and one or more times per day arriving mail will be picked up and securely transported to the bank.
Staff at the bank will scan the documents and may even deliver the physical copy back to the Provider. And here is where another difficulty is introduced: document scanning.
BIG IDEA: There are no standards for how EOBs are scanned.
Some banks will separate the checks before scanning, some scan them together wherever they happen to be in the document.
And other times the check will be separated from the document and scanned independently.
Paper EOBs usually arrive in a single envelope, but in the case of a very large EOB spanning thousands of pages, there will be multiple envelopes (another scanning headache).
Electronic EOBs
Electronic EOBs are almost exclusively received by healthcare clearinghouse companies through a secure FTP (SFTP or FTPS) service. However, it is sometimes possible to retrieve them by download from the insurance company’s website.
 These are typically in:
These are typically in:
- PDF (Portable Document Format) or
- TIFF (Tagged Image File Format)
Sometimes the PDF is a “searchable” PDF with the text on the EOB built-in to the document itself. This means that the electronic document will not need to be “read” by an optical character recognition (OCR) software (good news!).
Another electronic format for EOBs is a printfile version. These files are created by the software that does the actual printing of the EOB for the Payer. This method is unusual, but does provide a much higher quality posting file for the Provider.
To get this right, you need a very clear understanding of how the data is formatted so it will be correctly parsed for the Provider’s patient accounting system.
What is an EDI 835, and How Do Healthcare Clearinghouse Companies Process them?
The EDI 835 (or just 835) is a data transaction set called a Health Care Claim Payment and Remittance Advice.
It has been specified by HIPAA 5010 requirements for the electronic transmission of healthcare payment and benefit information. The 835 is primarily used by healthcare insurance plans (Payers) to make payments to healthcare Providers, to provide EOBs, or both.
When a healthcare Provider submits an 837 form (more on that later), the Payer uses the 835 to detail payment to the claim, including:
- What charges were paid, reduced, or denied
- Whether there was a deductible, coinsurance, copay, etc.
- Any bundling or splitting of claims or line items
- How the payment was made, such as through a clearinghouse
The general use of the phrase “Electronic Remittance Advice” (ERA) refers to the EDI 835. This format was developed by the Accredited Standards Committee (ASC) x12 committee. It takes into account the new ICD-10 codes. ERAs may be received directly from Payers or through a healthcare clearinghouse.
What is an EDI 837?
The EDI 837 (or just 837) is a data transaction format established to meet HIPAA requirements for the electronic submission of healthcare claim information. The claim information amounts to the following, for a single care encounter between patient and Provider:
- A description of the patient
- The patient’s condition for which treatment was provided
- The services provided
- The cost of treatment
837s are also commonly called “claims,” although claims themselves are also represented in various formats. Payers continue to push Providers to submit all claims to them electronically in the 837 format.
In case that sounds straightforward, take into consideration three different versions of the 837:
- 837I – Institutional (hospitals)
- 837P – Professional (doctors)
- 837D – Dental
The primary purpose of an 837 as it relates to healthcare data integration is to provide extra information not available in the 835 or on paper EOBs. It is also used to “backfill” information on the 835 that is available from a paper EOB, but may be subject to uncertainty from OCR errors when the EOB was scanned.
To use the 837, healthcare clearinghouse companies use intelligent document processing to pull enough information from an 835 or paper EOB to make a successful match. Fields necessary for this matching include: Patient Account Number, Patient Name, Date of Service, and Billed Amount.
Now, if a claim is submitted to the Payer by a healthcare clearinghouse, the 837 may be created from multiple sources. A clearinghouse will accept a UB-04 or CMS / HCFA -1500 form. These forms will be converted to an 837.
What is a CMS-1500?
The CMS-1500 is a form used for submitting claims.
As mentioned, it is also known as an HCFA-1500. The history of this form involved collaboration between HCFA (Health Care Financing Administration) and the American Medical Association.

The original form was approved in 1975, and over time underwent many modifications. It was renamed in 2001 to CMS-1500 when HCFA was renamed to the Center for Medicare and Medicaid Services (CMS).
Interestingly enough, this form was designed to be scanned with specialized scanning technology that “drops out” the color red to make data extraction easier. Although modern scanning software no longer requires this, the form’s format has not been updated.
What is a UB-04? (Not the band)
The UB-04 is a claim form also known as CMS-1450. This form was designed by the CMS in collaboration with the National Billing Committee and several others. It is used by institutional Providers, which generally refer to hospitals. The form is a modification of a previous form, the UB-92 which replaced the earlier UB-82.
The UB-04 became the standard paper form for institutional claims on March 1, 2007. Healthcare clearinghouses process this paper form into an electronic format to meet the 837I EDI standard.
Statements of Electronic Payment
Remember this document contained within an EOB? There are two files (read: document types) which communicate financial transactions (excluding a paper check) which must be read by the intelligent document processing solution. These are in BAI or ACH file formats.
What is the BAI File Format?
BAI is the Bank Administration Institute. The BAI file format was developed to perform cash management. The current version of BAI is BAI2.
This file is used by healthcare clearinghouse companies to determine the lockbox deposit amounts relating to the EOBs. It acts as a check for balancing deposit amounts against the amounts reported in an EOB.
What is the ACH File Format?
ACH stands for Automated Clearing House.
 This file format was designed to pass information about interbank transfers. The originator information is a single bank, and the destination is a single bank, but with multiple possible destination accounts.
This file format was designed to pass information about interbank transfers. The originator information is a single bank, and the destination is a single bank, but with multiple possible destination accounts.
The originating bank must send out an ACH file to each bank for which they need to process debits or credits for that day’s business.
There are several ACH formats. In healthcare data integration, the primary concern is the number of addendum records supported in the file. Each addendum record holds up to 80 characters. Here are the formats healthcare data processing is concerned with:
- CTX – This stands for Corporate Trade Exchange and is commonly used for invoices or healthcare payments. CTX transactions contain up to 9,999 addendum records. The CTX provides a wealth of information about a payment, including containing an entire 835.
- PPD – This stands for Prearranged Payment and Deposit entry. This format is commonly used for payroll payments and only supports one addendum record.
- CCD – This stands for Cash Concentration or Disbursement. It is commonly used for “sweep” payments. These are payments from one account to another within an organization or to make / collect payments from another corporate entity. This format supports only one addendum record.
Correspondences for Healthcare Clearinghouses
While most of what arrives in a bank lockbox or post office box are EOBs and payment information, general correspondence documents are also included.
These documents could be:
- Sales solicitations
- Legal documents
- Patient correspondence
- Requests for information
- Or any number of completely unrelated mail
Correspondence documents must be identified and processed accordingly.
Lockbox Information Files
Lockbox information files for healthcare clearinghouse companies relate to scanned document images. They contain information about the images which are used in healthcare data integration. These files are also referred to as “control” or “index” files.
 Every bank uses a different format, and sometimes more than one format. The file contains a reference to each scanned image, which physical envelope it came in, and the dollar amount on the check.
Every bank uses a different format, and sometimes more than one format. The file contains a reference to each scanned image, which physical envelope it came in, and the dollar amount on the check.
Some lockbox information files will contain other pieces of information like:
- The Magnetic Ink Character Recognition (MICR) information from a check
- The check’s serial number
- Transit / routing number
- Account number
- Scanning batch numbers
- Batch totals
- Lockbox totals
- And even Payer information

Patient Information Files
Payments from patients usually arrive at the lockbox service with only a payment stub and a check, or credit card information filled into a form. These documents present a problem.
While the patient’s name and general ledger account number are available, the Patient Account Number (or Encounter Number) is missing. The payment cannot be processed until this information is cross-referenced with an external database.
Healthcare Data Integration from Physical and Electronic Documents
Because of the wild variety of forms and information used in claims management, intelligent document processing (IDP) is an effective solution to modernize healthcare data capture and integration.
The benefit of using IDP is end-to-end data capture. IDP solutions include robust electronic data ingestion, document scanning, high accuracy OCR, document classification, data extraction, external database lookups, rules-based processing, data verification, and integration with revenue cycle management software and process automation systems.
Scanning Paper Healthcare Forms and Documents
The scanning process may seem simple on the surface. But do not be fooled – many roadblocks lie in wait.
Getting the scanning part right is critical for accurate OCR (more on that later). Bank lockbox, healthcare clearinghouse, and Provider scanning services often struggle to keep on top of scanner maintenance. As scanners collect dust and as parts begin to fail, scan quality quickly erodes.
 There is a secret to staying on top of scanner maintenance that is better than waiting to discover poor scans later in the process.
There is a secret to staying on top of scanner maintenance that is better than waiting to discover poor scans later in the process.
Here is a tip:
- Create a test batch of documents
- Scan the batch at least once a month
- Test OCR
Compare with known good results to see if a margin of error is exceeded. If so, scanner maintenance (or perhaps even staff training) is required.
Another method for testing scan quality is a built-in feature of intelligent document processing. Because IDP includes OCR and machine learning, accuracy weightings for character recognition are determined during image processing.
If the weightings fall outside a pre-determined threshold, then the remediation steps mentioned above will need to be taken.
How to Get Good OCR Scans of Healthcare Documents
An important factor for good OCR is scanning resolution. There is a fine balance for optimizing quality vs speed.

 The optimal scanning resolution is 300 DPI. Anything higher and data transmission / OCR time is unnecessarily increased. Anything lower, and the characters on the page end up being crunched together or do not contain enough pixels for accurate OCR.
The optimal scanning resolution is 300 DPI. Anything higher and data transmission / OCR time is unnecessarily increased. Anything lower, and the characters on the page end up being crunched together or do not contain enough pixels for accurate OCR.
While bitonal scanned images work best for OCR, IDP solutions use thresholding algorithms to make color and grayscale images acceptable. They will be converted to bitonal and provide great OCR results.
For smaller scanning operations, a scanner connected directly to the IDP solution will provide maximum scanning efficiency.
What About Out of Order, Missing, or Duplicate Scans?
Sometimes pages get out of order. IDP solutions determine correct page order by looking at page numbers. If an out-of-order condition is detected, pages are automatically rearranged, and a log is created noting the original page order based on customer preference.
What if there are no page numbers, or missing pages?
These conditions are usually caught by data validations built into the IDP solution. Patient records often span multiple pages, and data extraction models expect a certain data flow. If the expected values are not found, the suspect document and / or pages will be flagged for human review at the healthcare clearinghouse company.
In the case of lockbox scanning, missing pages (and sometimes the entire file) will need to be scanned again from the paper record and digitally inserted into the final electronic file.
Sometimes scanners jam. If the scan operator doesn’t restart the scanning process correctly after a jam, duplicated scanned pages are easy to introduce. IDP systems detect and flag these duplicates by analyzing page numbers and by performing an image, or OCR analysis.
Optical Character Recognition
OCR engines built into IDP solutions have parameters which control speed and accuracy. For healthcare data integration, accuracy is more important than speed.
OCR engines work on one page at a time. To increase speed, IDP uses an approach called multithreading.
 A single computer will process multiple single pages simultaneously using individual processing cores. As an example, the Intel Core I9 processors have up to 16 cores, and other processors such as the Xeon Phi have up to 72.
A single computer will process multiple single pages simultaneously using individual processing cores. As an example, the Intel Core I9 processors have up to 16 cores, and other processors such as the Xeon Phi have up to 72.
IDP solutions report every single character on a page, where it is found, and a confidence score for what the character was reported to be. In the case of low confidence, the solution will attempt to swap the character with a likely replacement.
After the replacement, natural language processing is used to see if the word containing the suspect character makes better sense. Additionally, custom-defined lexicons of words may be parsed to determine if the corrected word is a better fit.
There are many other OCR features and capabilities built into IDP that are outside the scope of this document. Read more here.
Document Classification
Classification is the process of identifying the information represented on a document. Each document type contains different information. Classification is used by IDP solutions to determine what data extraction model to use for extracting necessary information.
 Classification considers two levels of information:
Classification considers two levels of information:
- Identifying individual pages
- Use a mix of pages and determines unique document types
As an example, the first level of classification determines that a document contains a check, a blank page, a summary page, and a detailed EOB page.
Another document from the same Payer may only contain a check, a blank page, and a summary page. Despite coming from the same Payer, the IDP system will process each document with a different data extraction model.
What Happens When a Healthcare Claim Document is Incorrectly Classified?
Sometimes documents will be misclassified due to OCR or human error.
These documents are caught by IDP solutions when there is difficulty finding the expected data. Misclassified documents are routed to a human processor who will view the document and compare it to a master image of what that document should look like.
Upon determining the correct document type and applying the right classification, the IDP system will resume automated data extraction.
If the human processor determines there is no known document type for the misclassified document, a workflow is used to create a new data extraction model.
EOB Data Extraction
EOB data extraction models, or “templates” in intelligent document processing solutions extract information from a document for downstream data integration. These templates are run after performing full-page OCR and classification.
The Many Challenges with EOB Layouts
There are over 6,000 layouts of paper EOBs.
 Blue Cross Blue Shield operates in almost every state and virtually every state has a different layout for their EOB. Many states even have multiple layouts. United Healthcare has dozens of formats.
Blue Cross Blue Shield operates in almost every state and virtually every state has a different layout for their EOB. Many states even have multiple layouts. United Healthcare has dozens of formats.
There are hundreds of insurance companies in the United States (including large companies, unions, co-ops, and utility companies), and most of them have multiple formats. On top of this, there are many third-party administrators which have their own formats.
Some Payers even change the layout within the EOB itself. Certain Medicare Payers are well known for having separate layouts all within the same layout, such as:
- Denied claims
- Paid claims
- Pending claims
- Chargebacks
This makes automating healthcare data integration a very critical task.
EOB and healthcare document data extraction requires robust intelligent document processing.
But There is Hope for Healthcare Clearinghouses with EOB Data Problems
The good news is that there is a limited set of data that is possible on any EOB. There are around 60 unique fields of information to be extracted. No EOB will have all these fields. Most have around 25 to 30 of these fields.
 A significant complication is that EOBs have different names for what is essentially the same field of information on another Payer’s EOB. One Payer may call a field “Patient Account Number,” while another may call it “Control Number.”
A significant complication is that EOBs have different names for what is essentially the same field of information on another Payer’s EOB. One Payer may call a field “Patient Account Number,” while another may call it “Control Number.”
Occasionally, one Payer may have a field labeled the same as a field in another Payer’s EOB, but the fields represent different data and must map to a different output field in the 835.
Clearly, a robust mapping system must be in place to ensure data goes to the correct segment and field in the 835. The IDP mapping system must be able to allow for configurations by Payer and by Provider, as many Providers require customization of the standard 835 format.
What Kind of Data is Found on an EOB?
EOBs contain hierarchical data. There are three levels of data:
- Check Level – Contains information which is unique across an EOB. This consists of check, Payer, and Provider information.
For some Payers a single payment may apply to multiple Providers, so you may find multiple Providers on the same EOB. Sometimes, interest is paid at the check level, while other times it may be paid at the patient, or service line level. - Patient Level – Contains information which is unique per patient. There may be multiple instances of the patient level information on an EOB.
Examples include Patient Name, Patient Account Number, Claim Number, Member Name / Number, and sometimes Interest, and Remark Codes. - Service Level – Contains information for the service performed for the patient. There may be multiple service lines for each patient. The service line contains the deepest level of detail on an EOB. There are more fields at the service line level than at any other level.
These fields include Service Dates, Billed Amount, Procedure Codes, Diagnosis Codes, Copay, Coinsurance, Deductible, Allowed Amount, Denied Amount, Coordination of Benefits, Remark Codes, Amount Paid, and sometimes Interest.
Adding to the complexity of service line data is that several of the fields often have multiple values for a single service line. Sometimes monetary fields have multiple values, and usually in conjunction with Remark Codes.
For example, “Denied Amount” will sometimes be written on two consecutive lines within a single service line with two different Remark Codes describing the reason for denial.
The Challenge with Remark Codes
Remark Codes, sometimes referred to as “Denial Codes,” present a challenge for EOB processing because they come in several varieties:
- Footnote – These Remark Codes are enumerated in numerical or alphabetic order
- Payer Specific Code – This Remark Code is represented by one or more digits that is only meaningful to that Payer, e.g., HC, AA, FG, A1, etc.
- ANSI Code – This Remark Code is represented by an ANSI standard payment code, e.g., CO-42, or OA-23
- Mix – An EOB may contain a combination of Footnote, Payer Specific, or ANSI codes
- None – No Remark Codes shown, but a description is listed on the line it applies to, or below the patient information, or at the end of the EOB
- Line Number – A separate grid below the patient information indicates what line a remark applies to
Reconciliation of the Remark Code to the Code Description is tricky! The code descriptions may be below the service line on which the Remark Code appeared, or at the bottom of the patient information, or at the bottom of a page, or at the end of the document, or not present at all.
If the Payer is using standard ANSI codes, the description may be left off because it is already known. In this case, the code is plugged directly into the 835.
How Intelligent Document Processing Software Work With Remark Codes
If the Remark Code is a Payer Specific Code, the IDP system will compare it to an existing list which is built by the system along the way. If the code matches and the description is the same, then it considered a match.
The IDP system will maintain a list of these codes and descriptions by Payer and data extraction template. Upon discovery of the first new Payer Specific Code, the system will flag it for a review of the description and map it to a standard ANSI code for output to the 835.
Intelligent document processing systems use algorithms to compare remark descriptions. These algorithms account for word deletion, insertion, substitution, and accidental transposition of characters (often seen in hand-typed text mistakes).
Customers may wish to change the standard ANSI code mapped to a Remark Code. Even though the default code that is in the system may be the “right” ANSI code theoretically, some healthcare information systems will not allow certain codes.
For example, some of our customers will not allow a CO-A1 (Claim/Service Denied) even though it may be the right code for the circumstance. They may require a more specific denial code. In these situations, our IDP system allows customers to override the standard code which will be output for that description and substitute their own code choice.
How Healthcare Clearinghouse Companies Can Process Thousands of EOB Formats - Quickly
This document has revealed how many variables there are in EOBs and the different documents that are often attached.
Just how big a job is it to create data extraction templates for so many different EOB formats?
The answer is an intelligent document processing tool with a template auto-builder that mimics the way a human would work. This is different than robotic process automation because the information needed from healthcare documents is not always found in the same place on the document.
 These “templates” are not yester-year’s hard-coded layout-based templates, rather they use Smart Label classification and extraction technology.
These “templates” are not yester-year’s hard-coded layout-based templates, rather they use Smart Label classification and extraction technology.
Here is an overview of how Smart Label classification works:
- A user selects a portion of the document containing the header-level information
- The software automatically identifies key words that indicate a label such as “Check Date, Check Amount, and NPI,” for example
- The system will also look ahead in the document to discover the beginning and end of a claim
- The software finds appropriate values for these labels and in the case of dates or currency amounts, learns what format is being used and converts as needed
- As the system is building the template, it will also begin automatically applying rules that correspond to the fields it discovers, e.g., if there are “Totals,” then all “Billed Amounts” in a claim must add up to the “Total,” as well as the “Allowed, Deductible, Coinsurance, Copy, Late Filing Reduction, Other Adjustments, and Provider Paid” data
- The last piece of information the software must learn is where to find the remark descriptions. The system finds this location by comparing a known lexicon of words that are synonyms for “Remark Code Descriptions.”
How to Use Automated Rules in EOB Processing
As previously mentioned, the IDP software will use a purpose-built “rules engine” to process a data element.
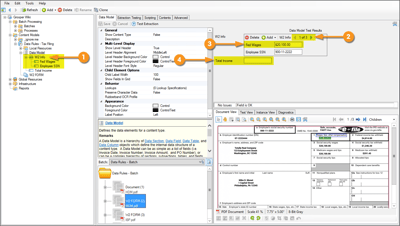 These rules are set up globally, per customer, per template, or on a Payer basis. They may be as simple as requiring the existence of a piece of data, or more complex, such as requiring data to match a certain regular expression, or mathematical validation.
These rules are set up globally, per customer, per template, or on a Payer basis. They may be as simple as requiring the existence of a piece of data, or more complex, such as requiring data to match a certain regular expression, or mathematical validation.
Rules may be put in place to require a Remark Code if the billed amount doesn’t equal the paid amount; or, to mathematically balance the service line horizontally and vertically. Rules are also implemented to require hand-keyed (corrected) data to be double-keyed by another person or to verify a patient’s account number.
How to Receive and Integrate Processed EOB Data
Most of our customers are sent one or more output files. Depending on their requirements and the primary contracted organization, the output files are picked up from an SFTP site, transmitted directly to our customer’s SFTP site, or transmitted to the bank’s SFTP site.
By 835
Most patient accounting systems will take an 835 EDI file. The 835 is the standard file output as designated by X12N.
However, customizations are nearly always requested. Some customers cannot accept an unbalanced ERA, and sometimes the paper EOBs just do not balance. In these situations, a Provider Level Balancing (PLB) record might be created.
There are also requirements for when the patient account number is not present in the EOB. The essential consideration for dealing with the outlier data problems is in creating a thorough onboarding document that covers the nuances of generating a correct posting file.
Other Posting Files
Some patient accounting systems are still not set up to intake an 835, but do allow custom import files. These may be fixed width, XML, comma separated, or some other format.
Patient Payment Output Files
Some accounting systems will take a “skinny” 835 to record a patient’s payment. This 835 contains only the fields which are found on the originating patient payment document. This is usually just the patient’s name, address, billed amount, and paid amount.
Accounting systems which do not accept any version of an 835 will allow for custom file imports for patient payment files.
Now is the time to improve operating earnings through better revenue cycle management with Grooper®, the leading healthcare intelligent document processing platform.



