
Looking at the results of my recent blood test got me to thinking about the difficulty of extracting data from PDFs.
Whether it's for personal use or an enterprise project involving hundreds or thousands of PDFs, I have some tips that can help you.
Table of Contents:
- An everyday example of tough-to-extract data from PDFs
- 4 Tips for Using Automated PDF Data Extraction Software - From an Expert
- How to Extract Data from a PDF Document
- Why Choose Grooper to Scrape Complex Data off PDFs?
Here's an Example of Tough-to-Extract (and Tough-to-Understand) Data from PDF Files
Ahead of an upcoming annual health checkup, I completed a blood test. Eager to see the results, I downloaded the test data as a PDF document from the new fancy web portal my provider offers. And wouldn't you know — it was not easy to read.
As a data professional, I know good labeled data when I see it, and this sure wasn't it.
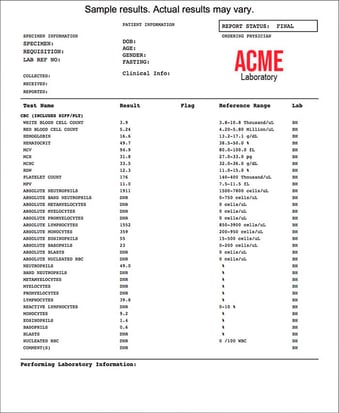 I've had more than 40 different blood tests performed on me over the last decade (I have high cholesterol - it's a genetic thing - so I watch my cholesterol numbers and triglycerides closely).
I've had more than 40 different blood tests performed on me over the last decade (I have high cholesterol - it's a genetic thing - so I watch my cholesterol numbers and triglycerides closely).
And I had no idea what most of the tests were.
Taking on projects is the best way for me to learn things. And I suspect that's true with most people.
So I gave myself a project to extract data from the bloodwork PDFs that I received. I then highlighted the data that were "out of range," (like my cholesterol if I don't take my medication).
By the end of a project like this, I may not know what the different tests are, but I will know my data. And I'll see the variations of data across different years (I get two tests a year on average).
The point I'm making here is that I had to get intimate with my data in order to use it properly.
Anyway, my recent bloodwork data project got me to thinking about a PDF data extraction demo I've been working on. Based on that, here are 4 tips I'll pass along below.

4 Tips for Using Automated PDF Data Extraction Software
PDF Data Extraction Tip #1: Understand the Reality of Your Data
Here's a recent scenario I faced: A client sent me 9 documents comprising 125 pages for an industry I've never worked in - Insurance. And, as expected, in a very unconsumable format.
 My project was to create a data model to extract that difficult data from PDFs.
My project was to create a data model to extract that difficult data from PDFs.
In every single PDF data extraction project I've come across, there's a gap between the customer's understanding of their data and the reality of their data.
And that's just how it goes and why outside eyes are a big help.
To perform this complex work, you'll need intelligent document processing technology. But don't lose sight of the fact that the reality of your data doesn't change — complex data extraction will always require a more complex solution.
PDF Data Extraction Tip #2: Start with Good Business Processes
So the demo I'm working on is focused on insurance estimates. To build models for data extraction, I need to know and start with the required data.
Thankfully, this client has their business processes fully documented and gave me a list of required fields. Knowing exactly what information is critical for downstream processes makes a proof-of-concept exercise much more valuable.
The reality of extracting data from PDFs is that some data may simply be too cost-prohibitive to collect without a clear understanding of the business outcomes.
Is the business outcome high-value? Then more time and costs should be allocated to the solution.
Download Our Guide to PDF Data Extraction!
Learn why AI can't automatically understand what's on your PDFs - and how to overcome it.

Download Free Guide:
BONUS TIP: There's a reason data scientists label their data.
If you don't know what you have, you can't model it!
PDF Data Extraction Tip #3: Use Key-Value Pairs (The Low-Hanging Fruit)
In my demo, I started off with something easy - a key-value field that looks for a "total cost" on the documents. It's always some variation of the word "total" and a currency figure in close proximity. That's what a key-value pair is.
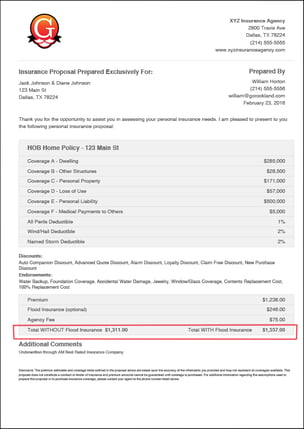 So I configured a key-value pair extractor modeled to look for this association of a particular word(s) and currency data nearby.
So I configured a key-value pair extractor modeled to look for this association of a particular word(s) and currency data nearby.
I'm working in the Grooper data extraction platform which makes it easy for me to step through each document one-by-one to test extraction results.
I can even click on "Test All" to test all the documents in the current batch (the nine documents with 125 pages), and I'll get a little red flag on any document where extraction failed to produce a result.
Using a Little Data Science for Easy Results
I see results in real-time and make adjustments to my data extraction model as needed.

This process is called Textual Disambiguation. It's a data science term that basically means creating a hypothesis and testing it iteratively.
That's what Grooper facilitates.
No other product I've ever worked with makes this iterative process so easy to do.
After configuring around 10 fields for extraction, I have a good idea of the data set I'm working with. I've iterated these documents at least ten times (once per extractor), and now I know the data really well.
PDF Data Extraction Tip #4: Use Data to Tell The Story
I can tell a story with the data as I demonstrate the proof of concept. For example, I can see things such as:
- "This document from XYZ Insurance Company doesn't have any adjuster name."
- "This one from ABC Indemnity was a malformed PDF."
- "And these over here — from Intelligent Coverage Co — are in great shape. And we can extract all the data needed."
Again, I've gotten intimate with the data set.
This is important for potential customers to know. The process of learning someone else's data, and becoming intimate with it, is iterative, and it takes time.
It's why we've gone to a different service model that helps facilitate this type of process rather than trying to figure out a Scope of Work in the presales cycle. This is something that, in my opinion, has always been contentious.
We have to learn a customer's data to really understand if what we're extracting is meaningful. But more than that, we have to be able to explain the data extraction story.
Here's Why Telling the Story of Someone's Data Extraction is So Important
We have to be able to explain the pros and cons of what we've found so that the prospect has a clear path to achieve their desired business outcomes.
 But this isn't an easy story to tell because it takes work.
But this isn't an easy story to tell because it takes work.
It's easier to just say, "We get 99.99% of your data, guaranteed." But anyone who says that without first really getting intimate with your data is just trying to sell you something.
And I'll bet good money it doesn't work.
Challenges in PDF Data Extraction Are Complicated
Issues dealing with data extraction take time to understand, unravel, and perfect.
 We're in a strange place in the automation industry right now.
We're in a strange place in the automation industry right now.
Companies are touting terms like AI and ML without really having any wood behind the arrow.
Just do a quick Google search on "Realities of AI," and you'll quickly see that most of what's out there is marketing hype at best.
So we built Grooper software to solve difficult problems like PDF table extraction, and classification. And the goal is to help users extract data from PDF files and scanned documents with little or no manual data entry.
We use several components of AI, and we're transparent about it. We've built the extraction tools you need:
- Computer vision algorithms
- Natural language processing (NLP) features
- Supervised Machine Learning algorithms for both classification and extraction
The key to extracting accurate information from complex data is how these innovative features have been combined to get data from PDF documents.
Why Choose Grooper to Scrape Complex Data off PDFs?
Because it Has PDF Data Extraction Tools Specifically Built for Complex Data
We didn't take off-the-shelf components (which haven't been built with PDF document processing in mind) and ram them into the product.
![]() Instead, our development team studies advanced data science techniques and discovers how to use them with PDF data extraction and automation projects.
Instead, our development team studies advanced data science techniques and discovers how to use them with PDF data extraction and automation projects.
We've built our own intellectual property into Grooper to be the best platform for extracting difficult data for demanding business processes.
If you're tired of vendors overpromising and underdelivering, give us a call. We'd be happy to discuss how Grooper can help extract data from PDFs, if it can.
And if it can't, we'll tell you that right off. And we'll even explain why.
How to Extract Data from a PDF Document
Ever since it was launched by Adobe in the '90s, the Portable Document Format (PDF) has become the go-to file type used everywhere for exchanging data in today's business environment. And it's easy to see why, as they make viewing, printing or saving data very simple.
However (unless you have Adobe Pro) pulling off, extracting, parsing or scraping data off PDFs is not quite so simple.
Here Are 4 Ways to Extract Data from PDFs:
- Good old-fashioned manual copy and paste - A good option
- Outsourcing manual data entry and data scraping - A better option
- PDF Converters - Decent option
- Automated PDF data extraction software - The best option
Manual Copy and Paste
Honestly, if you only have one to several dozen PDFs to extract the data out of, this is probably the best and most practical (but most painful) option. It is also by far the least expensive option — as long as there isn't too much work to do.
 A FEW EXPERT TIPS: This method only works with PDFs that were electronically created — not with PDFs that are scans of paper documents. Cursors can not grab data from scans as those sort of PDFs are essentially images taken of a document and the data is flattened pixels. But electronically created PDFs (PDFs created off of Excel files, Word, CSV or XML files) have data that can be selected manually by cursors as the data sits on a separate layer and it is not pixels.
A FEW EXPERT TIPS: This method only works with PDFs that were electronically created — not with PDFs that are scans of paper documents. Cursors can not grab data from scans as those sort of PDFs are essentially images taken of a document and the data is flattened pixels. But electronically created PDFs (PDFs created off of Excel files, Word, CSV or XML files) have data that can be selected manually by cursors as the data sits on a separate layer and it is not pixels.
Also, the more PDFs that there are to extract information from, this manual method becomes very cost-prohibitive as it is very time consuming and tedious (and is prone to manual errors).
Here are the steps for this method:
- Open the PDF document
- Use the cursor to select the segment of text on one or several pages
- Use your keyboard to copy the needed data
- This is usually done by pressing 'Ctrl + C' on a Windows machine or by right-clicking with your mouse and selecting 'Copy'
- Paste the copied text into your a XLS, DOC, CSV or other file
- On most Windows machines, the shortcut for pasting is usually 'Ctrl + V'. You can also right-click with your mouse and press 'Paste.'
- If using your mouse, it is recommended to select 'Paste as plain text' as it removes any formatting that the PDF used
- On most Windows machines, the shortcut for pasting is usually 'Ctrl + V'. You can also right-click with your mouse and press 'Paste.'
ANOTHER EXPERT TIP: If you are selecting table data, then my prayers go out to you as it is super tedious and painful. But you may try pasting the data first into a Word document, then copying and pasting it into Excel to retain the table's proper structure.
Outsourcing Manual Data Entry Work
If you have large quantities of PDFs documents to get data out of, then outsourcing the manual work is an option to consider. There are an overwhelming amount of companies that do this work, with most of those existing in low-income countries overseas in India or other Asian countries. So obviously the work can be done fast and cheap.
 There are also domestic options that can be found on Freelancer, Fiverr or Hubstaff talent. In both options, these companies employ armies of data entry clerks who repeat the steps described above.
There are also domestic options that can be found on Freelancer, Fiverr or Hubstaff talent. In both options, these companies employ armies of data entry clerks who repeat the steps described above.
A FEW EXPERT TIPS: Though this method of data entry can be completed quickly and on the cheap, it comes with it's own set of challenges. Many of these outsourcing companies claim to use the latest technology to automate this process, and as a result they claim to commit no manual data entry errors.
However that is hardly ever true. They are generally always using manual labor to extract the data. If they are using an automated data extraction software, it is probably not very powerful and have to supplement the software with lots of manual work to catch what the software did not.
As a result, quality control and data security are legitimate issues to consider. How sensitive is your data and how many manual errors are you willing to accept?
PDF Converters
 These middle-of-the-road options are a decent solution for handling extraction in-house, quickly and for a decent price. They be used as desktop software, web-based software, or on mobile devices and convert PDFs to Excel, CSV (comma separated values) or even XML.
These middle-of-the-road options are a decent solution for handling extraction in-house, quickly and for a decent price. They be used as desktop software, web-based software, or on mobile devices and convert PDFs to Excel, CSV (comma separated values) or even XML.
Several PDF tools include:
- Adobe
- Cometdocs
- SmallPDF
- NitroPro
- iSkysoft PDF Converter Pro
A FEW EXPERT TIPS: Many of these options are free, and while that's great, many times you get what you pay for (hint, hint). In addition, these tools only convert one document at a time. So if you have batches or hundreds of documents to process, it could take a long time.
And these converters are usually black boxes. This means you upload a document, get a result, and that's it. There generally aren't many settings you can fine tune to get a specific result in case you aren't getting a conversion result you don't like.
Automated PDF Data Extraction Software
These solutions are the top-of-the-line and can extract extract full data from PDFs with electronic data as well as PDFs that are scans of documents. Of course, they are the most expensive option but are efficient, secure, reliable, and extract batches of documents at scale very quickly. The time and cost savings they provide can be immense.
 These options are the best for scenarios that involve hundreds or thousands of PDFs that contain a lot of data, such as:
These options are the best for scenarios that involve hundreds or thousands of PDFs that contain a lot of data, such as:
- Invoices or transactional documents
- Purchase orders
- Transcripts
- Bank Statements
- Leases
- Contracts
These automated PDF data extraction solutions use a combination of many technologies to get superior extraction from tough documents. These technologies include OCR software (optical character recognition), computer vision, and image processing.
Here is a general workflow for how these tools work:
- Compile a batch of sample PDF documents to train the software on what data is to be extracted
- Train the software which data you want extracted. If there are different types of documents, you will train separate batches differently.
- Test to ensure that the training was correct
- Perform automated extraction on actual (non-test) documents
- Process the data and integrate it into your business intelligence or content management system
A FEW EXPERT TIPS: When training the automation, it certainly helps to have subject matter experts on hand to advise which data is needed. For example, if you are extracting data from Accounts Payable PDF documents, you should have an AP department official on hand to consult the data that is desired.
Download Our Guide to PDF Data Extraction!
Learn why AI can't automatically understand what's on your PDFs - and how to overcome it.


