
Do you still keep paper records? Are you scanning those documents, or considering having those document scanned?
Regardless of whether your paper situation is fully under control (or if it’s gotten way out of hand) simply scanning documents with the nearest scanner isn’t all that helpful.
Instead, using a scanner that's integrated with OCR technology provides many benefits over traditional scanning.
Here are 5 Benefits of Using OCR Scanner Software over Traditional Scanning:
Benefit #1: Traditional Scanning Puts Businesses at Risk
 Some of the risks that traditional document scanning poses to organizations include:
Some of the risks that traditional document scanning poses to organizations include:
- Where will the scanned documents be stored?
- How do I know if I got all of my scanned documents?
- How will I find my records?
- How can I secure any sensitive data?
- It's more time and cost-consuming to search through a computer than to just go find a paper file
- What happens if I lose the data?
The list goes on and on.
But OCR scanner software and intelligent document processing overcome these problems to securely store scanned documents in the location of your choosing.

Benefit #2: Smart PDF Storage and Organization
 When documents are scanned, they’re typically saved in PDF format. PDF is great because it works on any computer without expensive software.
When documents are scanned, they’re typically saved in PDF format. PDF is great because it works on any computer without expensive software.
Traditional document scanning is great for reproducing paper in PDF digital format, but it doesn’t solve your deeper problems (and sure doesn't help with formats like microform).
Traditional scanning does not make it easier to:
- Find
- Organize
- Or securely store your documents
In fact, it adds complexity and risk of losing important information.
However, document scanning with OCR converter software is the safe and smart alternative to traditional document scanning as it solves all of these problems.
Benefit #3: Your Business Information Systems Understand What Data and Information You Have
 To understand the difference between scanning with OCR scanner software versus traditional document scanning, think about the last time you saw a web page or article in a language you didn’t know.
To understand the difference between scanning with OCR scanner software versus traditional document scanning, think about the last time you saw a web page or article in a language you didn’t know.
You could see the content just fine, and recognize the letters, but the content didn’t have any meaning to you. So when you scan documents without creating an awareness of the content, it’s the same thing.
Your information systems have no clue what’s there. And it makes sense.
There’s all kinds of different documents you work with. It's not thousands of copies of the same form.
How’s a computer to know what’s what?
BIG IDEA: Rather than just making a simple PDF of documents, wouldn't it be infinitely better to:
- Make a digital copy of your paper records
- Interpret the data that’s on them and
- Move that exact data into your information systems
Intelligent OCR processing software not only reads your documents, but understands the content and moves specific information into your information systems along with a human-readable PDF image.
It’s like going back in time and capturing everything in a software application instead of just on paper.
OCR scanner software is the singular solution to eliminate both fear of digitizing records and cost of manual data entry (because, let's face it - you could hand-key everything, but that is time-consuming, painstaking and can have errors).
In addition to OCR scanner software, document scanning services that use OCR software also exist to make document scanning even easier.
Benefit #4: Accurate Data that You Can Trust Scanned with OCR Software
 You have to be able to trust the data that was recognized and extracted, which is the OCR accuracy. In order to assure that high-quality data is entered into your information system, the software performs validations like financial and date calculations, and flags any discrepancies for human review.
You have to be able to trust the data that was recognized and extracted, which is the OCR accuracy. In order to assure that high-quality data is entered into your information system, the software performs validations like financial and date calculations, and flags any discrepancies for human review.
Additionally, your existing databases can also be used to validate known information like:
- Invoice / account / case / matter numbers
- Costs
- Totals
- Names
- Any other specific index
Benefit #5: Streamline Workflows, Increase Profits and Cut Costs with OCR Scanning Software
 So, now that you have all of this extra data, how do you use it?
So, now that you have all of this extra data, how do you use it?
You choose how to integrate document data and where it goes. But the possibilities to improve your organization (and decrease costs / increase profits) are numerous:
- Merge information into existing databases
- Better understand internal operations, and where inefficiencies are
- Learn more of how third-party vendors are treating your business
- Scrub confidential data
- Create multiple versions of PDF documents (maybe you need the original and also one with redacted info)
- Create spreadsheets
- Integrate data into business intelligence platforms to see past data and identify future trends
Cheat Sheet: Discover the Secrets Used by the Best OCR Scanner Software
Hopefully you can see why simply scanning documents with the nearest scanner is not the smart choice and why reading data from documents with OCR is a much better solution.
In addition, there are several elements that lead to superior OCR data recognition results. In this Guide to OCR, you can learn from document processing industry experts what leads to the best results in OCR scanning.
In the OCR Software Cheat Sheet, discover:
- The 7 best technologies required for best OCR and scanning
- What things hurt scanning and OCR accuracy
- How OCR scanning works
- The 2 technology patents from the U.S. Patent and Trademark Office that Grooper OCR uses to get the best OCR scan results

Many Scanners Include OCR Software - What Does OCR Software Do?
 OCR software uses a scanner to capture an image of a document, and optical character recognition technology to then recognize and find numbers and letters on those scanned documents, photos, or images.
OCR software uses a scanner to capture an image of a document, and optical character recognition technology to then recognize and find numbers and letters on those scanned documents, photos, or images.
OCR software can recognize machine-created text or even handwritten text (by using intelligent character recognition).
That text is then extracted, processed and turned into machine-readable text that can be moved into, stored, and analyzed in other software, like content management systems or business intelligence software.
Suddenly, data that was once trapped on a page is now able to be found through searches or used to make important decisions.
Why OCR Scanner Software is Important for Machine-Readable Documents
The first step in getting OCR software to read like a human is converting documents to a machine-readable version. Humans understand the intent of a document just by looking at it.
Tables, cells, the structure of the document, and labels tell us everything we need to know. But software can’t read documents so easily.
Here's an example of how machines have trouble reading documents:
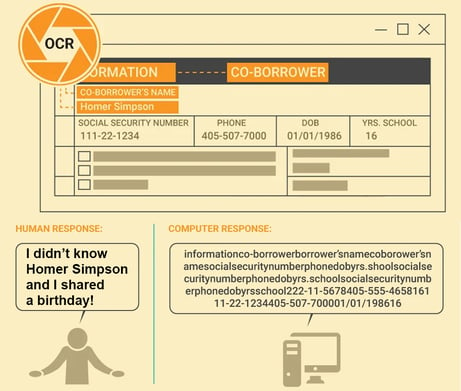
The best attempt so far at getting machines to read documents has been with OCR scanner software. And it doesn’t work all that great on paper documents. It tries to interpret everything on a document as a letter or number.
For example, the letter “I” is easily confused with a 1, or an l or L or an i. And when OCR sees lines or other non-text marks on a document, the results are ugly. You can’t trust this data or make business decision on it.
Check out this article which does a nice job showing real-life struggles on a simple receipt.
How Software Makes Data Recognition Easier for OCR Solutions
In order to create a machine-readable version of a document, everything must be removed that isn’t text.
Then, the important elements that make up the structure of the document must be added back in because they provide the context for how the software will interpret text on the page.
This part of the process is simple, as the software will:
- Remove everything that isn’t text
- Read the text
- Then add back in the document structure and interpret the meaning of the text
How OCR Software Engines Help Recognize Other Fonts and Handwriting
And to do a really good job of reading the text, the machine will need to use multiple OCR tools (we call them engines). One OCR engine might be better with handwriting, while another is better at reading those odd fonts on checks.
This image is an example of a document that has different fonts (and even handwriting) on one page:

Now the software knows what’s on the page and the meaning of specific data elements like:
- Dates
- Numbers
- Quantities
- Line items
- Addresses
- Checkboxes, etc.
Your job is to tell the machine how you want to integrate the data within your information system(s). Easy!

What are Some of The Best OCR Software for 2022?
Grooper OCR
Grooper OCR includes comprehensive image processing capabilities to help scans look as clear as possible for best possible text recognition results. A patented technology in Grooper is Layered OCR, which runs using multiple layers to derive the best total results which are combined in a final output.
A comprehensive globalized multi-language database is included. The language subsystem recognizes 268 distinct languages and 523 regional cultures.
Pros:
- Integrates easily with Sharepoint and Dropbox
- Excels at capturing data in tables, multi-page tables, or forms
- Several options available, including full enterprise or desktop OCR version. So there is a solution and price to make it very useful and cost-effective for any size of business, from small to medium sized all the way up to very large enterprise companies.
- Vast multi-format import - You can import files in PDF, JPEG, RTF, PNG, JPG, and PPT. And though electronic formats don't use OCR, even CSV, CMIS, XML, JSON, XSLT, etc.
Adobe Acrobat Pro DC
In addition to its many other document capabilities, Adobe Acrobat Pro DC features built-in OCR functionality. This aspect enables users to convert scanned documents into PDFs with editable electronic text very quickly or extract text from from PDF files.
Adobe also recognizes text in order to match fonts accurately when converting text into PDFs.
Pros:
- Stable
- Good for record archiving
- Free version is easy to use
Cons:
- Lacks features as it is not a dedicated OCR software
- Tough integration with Dropbox or Sharepoint
- Requires lot of hard disk space
ABBYY Finereader
ABBYY FineReader PDF is an OCR solution that takes files from a scanner and converts them into a readable, organized digitized document. In addition to recognizing and converting text into electronic text in PDFs, Microsoft Office or other various formats, Abbyy can also compare documents in different formats, or add comments / annotations.
Pros:
- Automates digitization and conversion routines
- Exports or converts PDFs to multiple formats such as Microsoft Excel, Word and more
- Capability to separate PDF files by pages, bookmarks or file size
Cons:
- Incapable of reviewing history of document changes / versions
- Incapable of full-text indexing for fast searching
Readiris
Readiris uses a very simple accessible interface with a lot of needed features to make for a good OCR scanner software option. It is a cost-effective option for small businesses with PDF, Pro, or Corporate-level packages.
In particular, Readiris empowers users to edit, convert and transform all paper document scans into your choice of digital format with just a few clicks. When it comes to PDFs, Readiris enables users to edit and annotate, aggregate and split PDFs, or sign and protect them.
It also supports other abilities that attach watermarks, annotations or comments inside documents.
Pros:
- Supports a variety of output formats, including Microsoft Office formats (like Excel, Word, or PowerPoint) or PDF
- Compatible with many operating systems and Twain scanners
- Ability to edit most embedded text in images
- Readiris recognizes over 130 languages
- Multi-format import - You can import files in PDF, DOC, JPEG, RTF, PNG, JPG, PPT and more
Cons:
- The optical character recognition engine included has trouble with tables or data inside boxes. Non-text elements close to text such as splotches, logos, hole punches, etc. tend to interfere with capture accuracy.
- No business card scanning
- Has data accuracy problems with unstructured forms of data
OmniPage Ultimate
OmniPage is meant for businesses who demand more out of their OCR, and includes more complicated features depending on which version you select. It is a more powerful OCR scanner software that can handle larger batches of business document OCR workflows.
After scanning, this software can convert your paper files, making them editable and searchable. With OmniPage, users can scan documents to any format and send them anywhere on the business's network.
Pros:
- OmniPage can support a broad range of formats or applications, including the Microsoft Office Suite, HTML, PDF, Corel WordPerfect, etc.
- Allows users to create custom workflows to automate frequent tasks
- Supports character recognition for over 120 different languages
Cons:
- Interface is complicated and not intuitive, especially for invoice automation
- It has trouble with complicated tables or forms
- Not very accurate
SimpleOCR Freeware
Well...it's free for personal or commercial use. That's about everything good you can say about SimpleOCR. The interface is outdated, clunky and doesn't appear that it's been updated since version 3.1. It really only handles very basic text recognition well. Anything else is a struggle.
According to it's own website, it doesn't recognize handwritten text, though other sites claim SimpleOCR offers handwriting extraction only as a 14-day free trial. It uses a lexicon (word dictionary to recognize words) of over 120,000 words. If there is a word it does not recognize, you can add new words via the text editor. It also supports English and French language recognition.
As with any other scanner software, it works with all versions of Windows and needs only a TWAIN driver to be compatible with the scanner. The image retention feature is used to capture and retain images from documents instead of needing to import images individually.
Pros:
- In the data validation phase, there is a built-in spell / error checker to find and correct errors in the converted text. This text editor tool highlights possible errors to help cut down on manually proofreading for spelling or other textual errors
- Batch OCR processes many documents (known as a batch) together
- As with many other OCR scanner software, SimpleOCR offers a despeckle option to clean up "noisy document" or those with a lot of specks or non-text junk that happened in the scan process. By removing this junk, it's designed to increase the text recognition accuracy of unclear copies and faxes.
- The 'Format Retention' feature helps retain needed parts of the original document's format. It can help you keep formatting elements such as font size, bold, underlines, and italicizes.
- You can view images directly from scanners in JPG, PNG, GIF, TIFF or BMP formats. Converted files can be saved in a DOC or TXT format
Cons:
- Rough interface
- Struggles mightily with text recognition out of tables and columns


