Check processing software has undergone many changes since the introduction of magnetized MICR fonts.
We built a check processing solution without machine learning using our intelligent document processing software called Grooper.

There Are the 3 Obstacles to Check Processing:
- Multiple font types (including MICR)
- Handwritten text
- Skewed images (pictures taken by a mobile phone)
We wanted a simple and accurate solution that didn't rely on machine learning and could work with any document scanner or camera.
Don't get us wrong - machine learning is amazing.
But There's a Surprising Thing Machine Learning is Not Good At...
Machine learning accuracy is not always on PAR with other approaches to data extraction. There are times human logic is more elegant and effective.
 In the world of intelligent document processing, machine learning is certainly the answer for content classification and it makes it possible for algorithms to perform accurate abstraction of all types of data.
In the world of intelligent document processing, machine learning is certainly the answer for content classification and it makes it possible for algorithms to perform accurate abstraction of all types of data.
And it's great for discovering the needle in the haystack. Machine learning never gets tired and works relentlessly when we ask it to.
But processing checks takes a different set of rules...
Machine Learning is No Good at Check Processing
There's a surprising use-case that proves machine learning isn't always superior. And that's with check processing. Understanding this use-case will help paint a picture of the complexity of "simple" data extraction projects.
In this article, we break down the steps needed to accurately extract information contained on a check - elegantly, efficiently, and quickly - with human logic and layering optical character recognition solutions.
A check presents an interesting problem for machine reading. Take a look at a check:

Count the different types of information. What did you come up with?
- Background image / border
- Payee information
- Date
- Check number
- Pay to the order of
- Amount of check (twice)
- Bank information
- Memo field
- Signature
- Account number
- Routing number
So, there are really 12 elements (more if you count bad check images from poor capture!) that must be handled to extract accurate data from a check.
How to Build a Check Processing Solution Without Machine Learning
Step One - Prepare for Optical Character Recognition (OCR)
This is where the check image itself is worked on. We used image processing tools to correct problems resulting from scanning, phone cameras, and to remove all non-text elements (except for handwriting!).
The result of image processing is a single document that contains nothing but text and handprint.
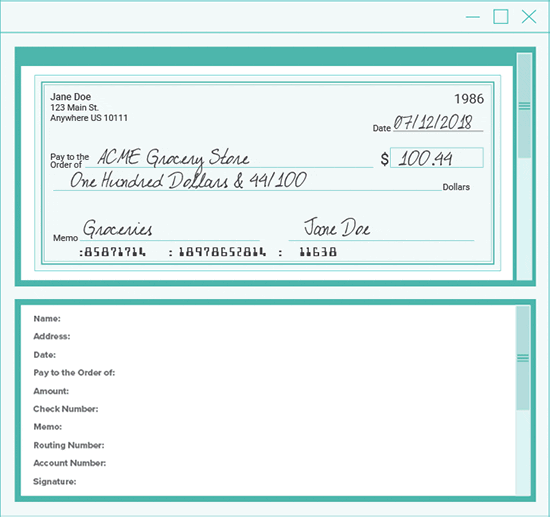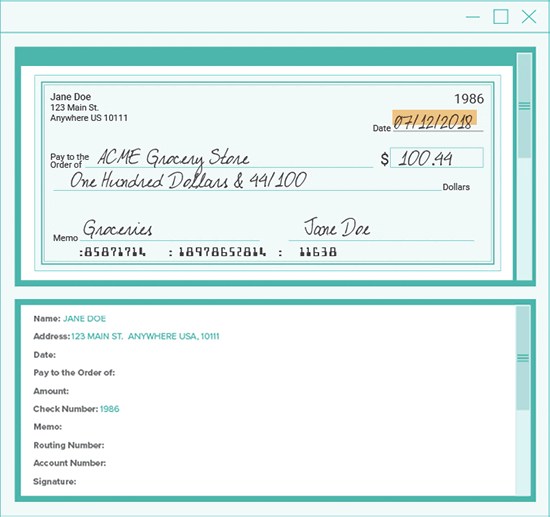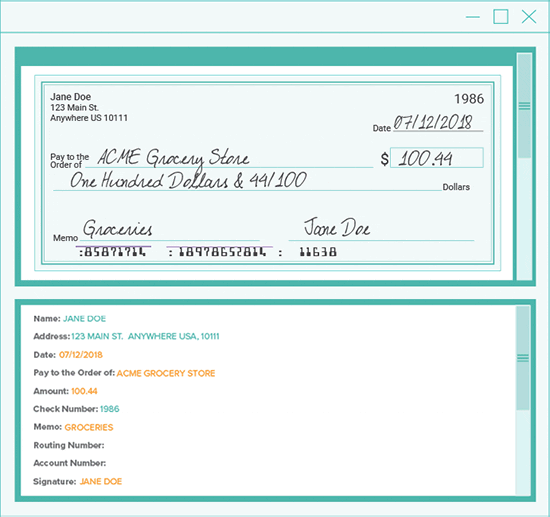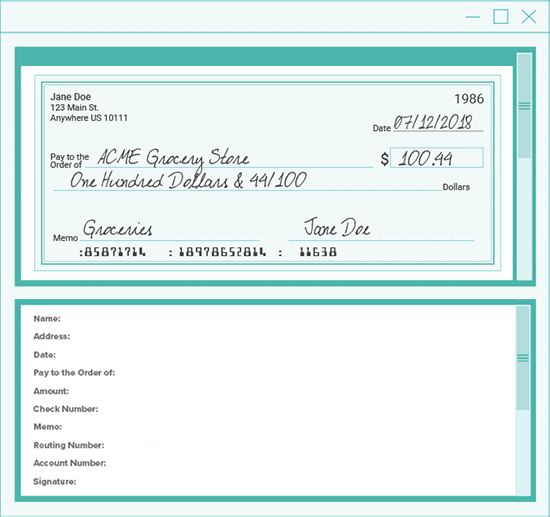
 Step Two - OCR
Step Two - OCR
For this step, we used multiple OCR engines. One engine processed handwriting (we used Azure Cognitive Services), and another engine (Google's Tesseract) to process the weird account / routing number text (MICR font) and the traditional fonts on the check.
We combined all the results into a single output. This let us verify that the amounts in the handprint all matched up and that the correct account and routing numbers were recognized.
Step Three - Logic (not Machine Learning)
Pattern matching to the rescue! Because OCR is never 100% accurate, logic is used to verify and format collected information from Step Two. Using regular expressions for pattern matching, all needed information is quickly corrected and collected. No need for machine learning because in this case, logic is king.
This is a good example of the challenges and problem-solving required in data science. With all the data science tools and techniques available, any data extraction project is easily automated.
If you're a curious person and want a deeper dive into Grooper software for check processing, take a look! Also learn about our many AP automation solutions!
Get Our Video: Check Process Automation Demo
Do you have a bad scanned image of a check or variety of different image qualities on different checks? Many companies face this challenge of getting all data captured off checks and other financial documents - even automated handwriting recognition!
Watch how our automated solution can help you accurately recognizes and extracts all text, saving you significant time and money! Our Check Processing experts will walk you through this 17-minute demonstration to explain how this software recognizes data that others can't!
WATCH THE VIDEO:



