
So, you’re here because you need to OCR data on text documents for full-page search or data extraction. Great!
OCR software is a bit like a video game, and the problems attacking good OCR are the 'villains'. As you'll see, there are ways to beat these villains, to get far better OCR text recognition.
The benefits are:
- Cost savings (reducing manpower needed for manual entry)
- Increasing profits (bringing new solutions to market quicker)
First, What is OCR?
Most people who have heard of text OCR think of it as a feature included with another piece of software to perform word searches. OCR is really just an algorithm that recognizes known characters on a page.
Optical Character Recognition, or OCR, has essentially been around since 1913. First used to interpret Morse code and assist the blind, OCR technology has continued to evolve. Grooper OCR technology is the pinnacle of this evolution by the creation of intelligent digital awareness of a document. More on that later...
 Using OCR text recognition technology, a computer compares patterns made by letters and numbers on scanned documents to a set of characters stored in the software. It can then automate time-consuming tasks like data entry.
Using OCR text recognition technology, a computer compares patterns made by letters and numbers on scanned documents to a set of characters stored in the software. It can then automate time-consuming tasks like data entry.
If OCR and the process of digitizing text is like a video game, then patterns make up the rules of the game.
We want our computer software to reliably recognize patterns, or pattern matching won’t work, and we won’t fare very well at this game.

How to Beat Poor Scan Quality and Low Contrast Images
As OCR works to recognize patterns, many things confuse the technology and cause problems. To give you an accurate digital conversion, OCR needs black and white scans that are at the perfect resolution (quality).

Having a black-and-white scan creates high image contrast, making the job simpler for OCR. When it comes to resolution, a low resolution scanned image of a document creates a lot of "noise" around the text letters and numbers, confusing OCR.
Low black and white contrast and poor resolution are the villains that we must beat. Thankfully, image processing tools have come the rescue to help us defeat these villains.
Using these tools will give you great black-and-white images, giving you the best starting point for OCR. Later, fuzzy data extraction will overcome poor resolution on PDFs or other image files. But there are many more tough villains ahead of us to defeat. Lucky for you, we have the cheat OCR codes for this game.
The Tools - or “Cheat Codes” - to Overcome OCR Text Villains
Here are the villains we're fighting:
And here is the master cheat OCR code we can use to beat all of these villains:
Just like any good cheat code, these let you break the rules of the game. These cheat OCR codes, or tools, allow Grooper to overcome typical problems associated with full text character recognition. In the past you only got one pass at an entire page of relatively complex symbols to get it right. No longer.
 Each one of these tools that Grooper uses to win the OCR game help it understand where problem areas are, hone in on those, and get as good an OCR read as possible.
Each one of these tools that Grooper uses to win the OCR game help it understand where problem areas are, hone in on those, and get as good an OCR read as possible.
Let’s take a look at each one.
Level 1 Villain: Boxed-In Text (Also known as Bounded Regions)
Cheat OCR Code: Bounded Region Detection
 A bounded region is whitespace surrounded by lines. Or simply put, text in a box.
A bounded region is whitespace surrounded by lines. Or simply put, text in a box.
Imagine an invoice, purchase order, or delivery receipt. These kinds of documents are comprised of text in tables and boxes.
Using Bounded Region Detection, Grooper finds those boxes, looks only at what’s inside them, and gets a great read on the contents.
Grooper just took what has typically been a nightmare for legacy image cleanup software to get rid of and used it to its advantage. It’s like a judo master that took someone twice their size running at them and used their momentum against them to flip them on the ground…with just his pinky.
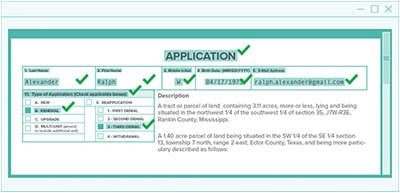 Check out a great example of bound region detection here.
Check out a great example of bound region detection here.
 Level 2 Villain: Segments
Level 2 Villain: Segments
Cheat OCR Code: Segment Reprocessing
A segment is a small block or line of text on a page. If any segment gets a low OCR text confidence score, Grooper uses Segment Reprocessing to run OCR on that segment a second time.
The outcome is better results for each of these troublesome lines.
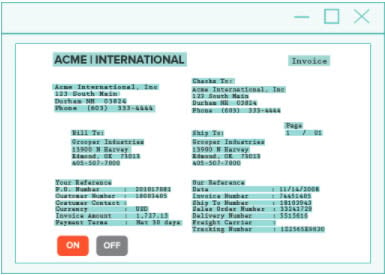 Check out a great example of segment reprocessing here.
Check out a great example of segment reprocessing here.

Level 3 Villains: Different-Sized Fonts and Free-Floating Text
Cheat OCR Code: Iterative Recognition
Documents frequently use different-sized fonts and free-floating text that are't in alignment.
OCR software reads pages from top to bottom and left to right like we do. Therefore, if fonts on the left are of a different size or are out of alignment with text on the right side, typical OCR generates poor results.
Grooper solves this problem with Iterative OCR, or by reading the document multiple times. The first time, it will read everything.
The second time, using Iterative OCR, Grooper will drop out what it read well, and then only read what was previously read poorly.
The dropped-out text will no longer interfere with remaining text, resulting in a much better read. This process repeats until the villain has been defeated.
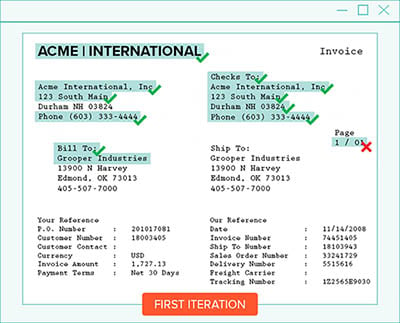 Here's an example of iterative OCR at work.
Here's an example of iterative OCR at work.
 Level 4 Villain: Multi-Column Layouts
Level 4 Villain: Multi-Column Layouts
Cheat OCR Code: Cellular Validation
A page with two or more columns presents a challenge for typical OCR text software.
Text in columns may be different font sizes, or the lines may be offset from one another. Many OCR processes will have a total breakdown and produce very inaccurate results.
However, Grooper uses Cellular Validation to create highly customizable OCR regions by splitting a document into specific rows and columns.
Rows and columns are defined by the Grooper user who understands the document’s structure and layout. Grooper then reads each of the individual rows and columns independently, understanding the difference in each section and how each section relates to the overall document.
 Watch cellular validation at work.
Watch cellular validation at work.

The Cheat Code: OCR Text Synthesis
Grooper combines the data produced from Bounded Region Detection, Segment Reprocessing, Iterative OCR, and Cellular Validation into one logical text flow.
Advanced font awareness re-analyzes spaces, tabs and new line feeds during OCR Synthesis.
Grooper ensures that all characters in a document are not just recognized but are assembled together in logical groupings. This is especially useful for check processing.
OCR text Synthesis sets Grooper apart from traditional OCR systems by providing a much-improved foundation for accurate and reliable data capture.
Beating the OCR Text Game
Grooper has the instant-win button, the buzzer-beating 3 pointer, the ability to instantly learn Kung Fu by plugging into the Matrix, the - well, you get the point.
But here’s the rub: few things in life are ever 100%, and perfect OCR results are one of them.
Not even with Grooper’s awesome cheat OCR codes can any recognition technology recognize and accurately convert 100% of a document’s text. But with these tools, or cheat codes, we are far closer to perfect text than we were previously.
I wish you the best in your document processing tasks and happy OCR text processing!



