
As a back-end provider of loan servicing software, we’re often asked about best practices for automating data integration.
There are definitely a handful of other vendors out there who do this. We'll arm you with the information you need to find the best one for your needs.This article also will mention several other vendors you may wish to consult.
Do These Loan Software Problems Sound Familiar?
If you are searching for mortgage automation software, chances are:
- You are dealing with a manual data entry problem
- Loan applications are taking too long to process
- Your post-close audit processes needs improvement
Regardless of whether you are streamlining the entire process or need to buy more profitable loans, getting accurate data upfront is crucial.
 We're seeing increased interest in automating loan processing and we're hearing that Encompass is becoming more expensive (especially now that they own Capsilon), and the new URLA is dynamic...
We're seeing increased interest in automating loan processing and we're hearing that Encompass is becoming more expensive (especially now that they own Capsilon), and the new URLA is dynamic...
Previous legacy automation solutions like Ephesoft, Captiva, and Kofax struggle to provide return on investment now that more data must be manually entered.
Credit unions, banks, and title companies are looking for new ways to maintain loan profitability throughout its lifecycle while future-proofing document-based mortgage automation workflows without a major rip-and-replace software change.
Imagine eliminating offshore processing and rapid post-close audits — and validating loan information in less than ten minutes per loan.
Sound great?
Let’s assume your processes are all very manual. You receive paper folders with hundreds of different document types, and the process starts there...
Here are 4 Factors That Are Most Important in a Loan Servicing Software:
- How will documents get into the system?
- How easy is it to classify different document types?
- How will information be identified and extracted?
- How is extracted information integrated with other systems?
Factor 1: How Are Loan Documents Getting Into Your System?
 Because there may not be a way to fully control the source of documents, there must be a way to import paper and electronic files. If you are processing hundreds of thousands or millions of pages of loan documents, you need to get them into your system as efficiently as possible.
Because there may not be a way to fully control the source of documents, there must be a way to import paper and electronic files. If you are processing hundreds of thousands or millions of pages of loan documents, you need to get them into your system as efficiently as possible.
Scanning the paper documents will be a part of the process even if you receive some loan packets electronically.
Integrate Your Scanners with Loan Servicing Software
Do not scan to a folder on your computer or server! This is too slow and creates problems with securing sensitive information. Even cloud-based scan modules provide significant bottlenecks transferring large volumes of documents.
What you need is a loan servicing software with production-level scanner hardware integration. By controlling the physical scanner itself, the hardware will be able to run at maximum speed and resolution. This gives the software full control over the quality of page images you are creating – because at the end of the process you still need high-quality document images.
Clean Up Scanned Images with Automation

The loan software will simultaneously scan the paper and clean the resulting scans by removing imperfections like hole punches, staple marks, smudges, and anything else that shouldn’t be on the final document image.
You will also need the same level of control when importing electronic documents.
Just because someone else did the scanning doesn’t mean the documents were scanned perfectly. The same amount of cleanup will need to be applied.
If you need to process documents stored in an existing content management system, the automation software will just as easily connect to it and process the files where they are without having to download them or move them around.

Factor 2: How Easy is it To Classify Different Document Types? End Manual Classification.
Document classification (also called indexing) is just the process of determining which pages make up an individual document. Some documents may be just one page, while others are made up of multiple pages.
 Asking a human to perform this task is time consuming. Even inserting barcode separator sheets before scanning is too time-consuming and introduces unnecessary errors.
Asking a human to perform this task is time consuming. Even inserting barcode separator sheets before scanning is too time-consuming and introduces unnecessary errors.
How Automated Document Classification Works
A modern loan servicing software will be pre-trained to automatically recognize which pages represent the beginning and end of a full document. The completed document will be named however you want, and all pages grouped together automatically.
Classification is one of the easiest functions that loan servicing software provides. There are many technologies that make this possible, like:
If you have a technical background, learn more about how to train a mortgage automation software here.
Factor 3: How Will Information Be Identified Within the Documents?
Scanning and classifying loan packets is really the easy part.
However, working with the information contained within the packet requires a little more sophistication. What needs to happen within the automation software is essentially the machine “reading like a human.”
This machine reading concept is fairly new. If you’ve worked with document capture software before, you know that the only way to “read” information on a page was to create a template telling the software exactly where to find certain information.
Using Machine Learning on Loan Documents
This template-based approach works pretty good when the document structure doesn’t change, but does a very poor job with documents that are variable – like the new URLA.
The Closing Disclosure might have one, two, or more columns of data. If you can’t predict exactly where the data is, how is it to be extracted?
Here’s where machine learning comes back into play again. It is used to classify document types, and it is also used to identify information on pages that are laid out in tables or nested tables of data.
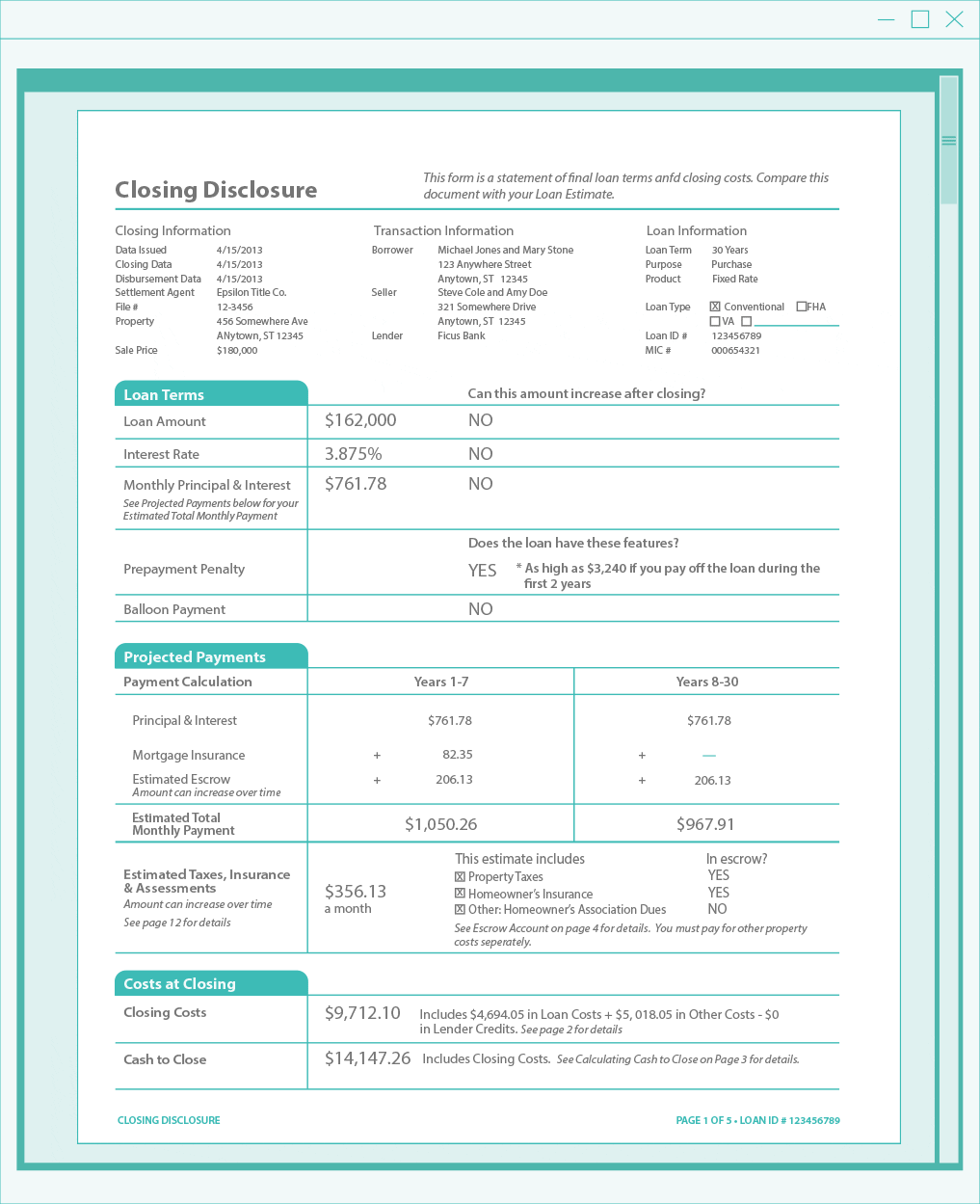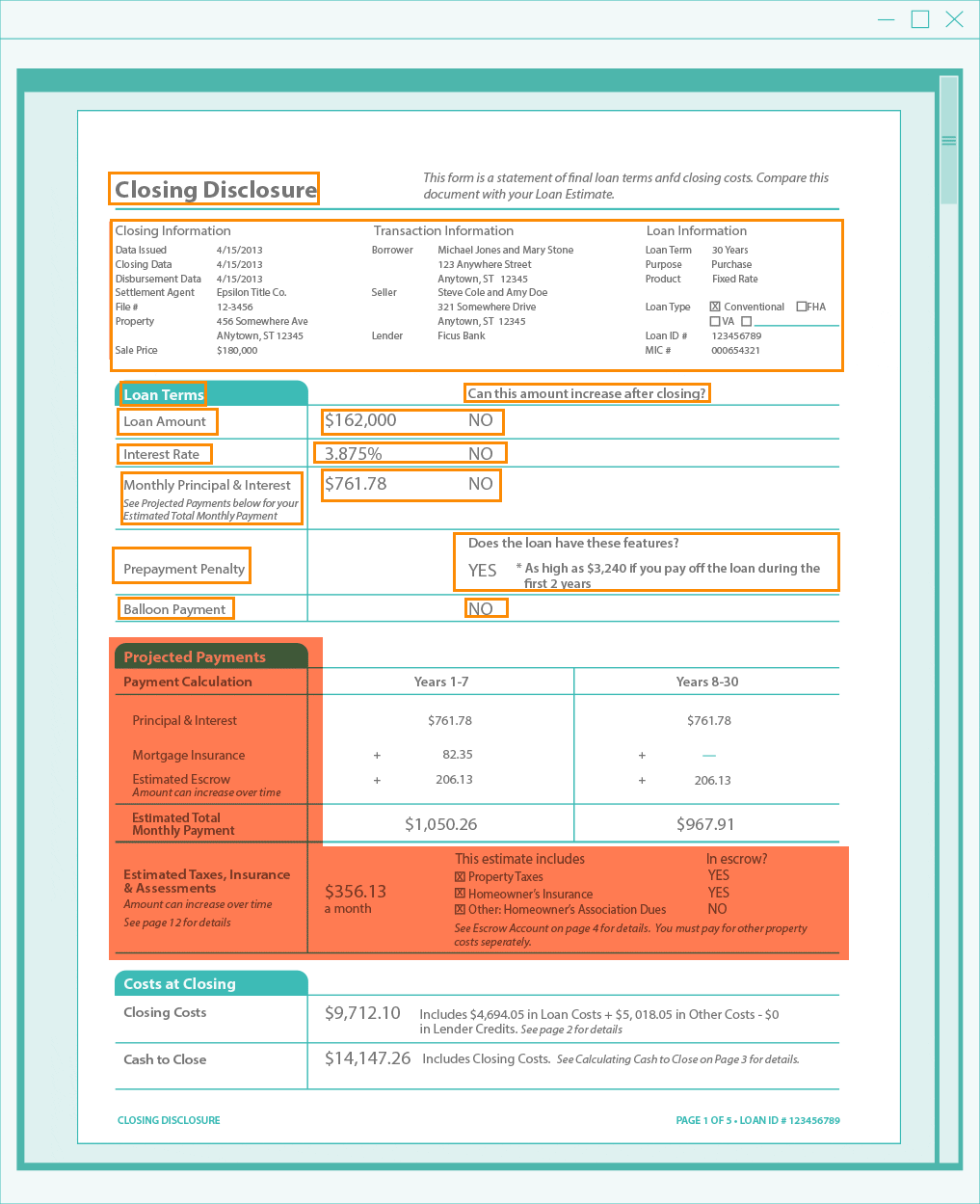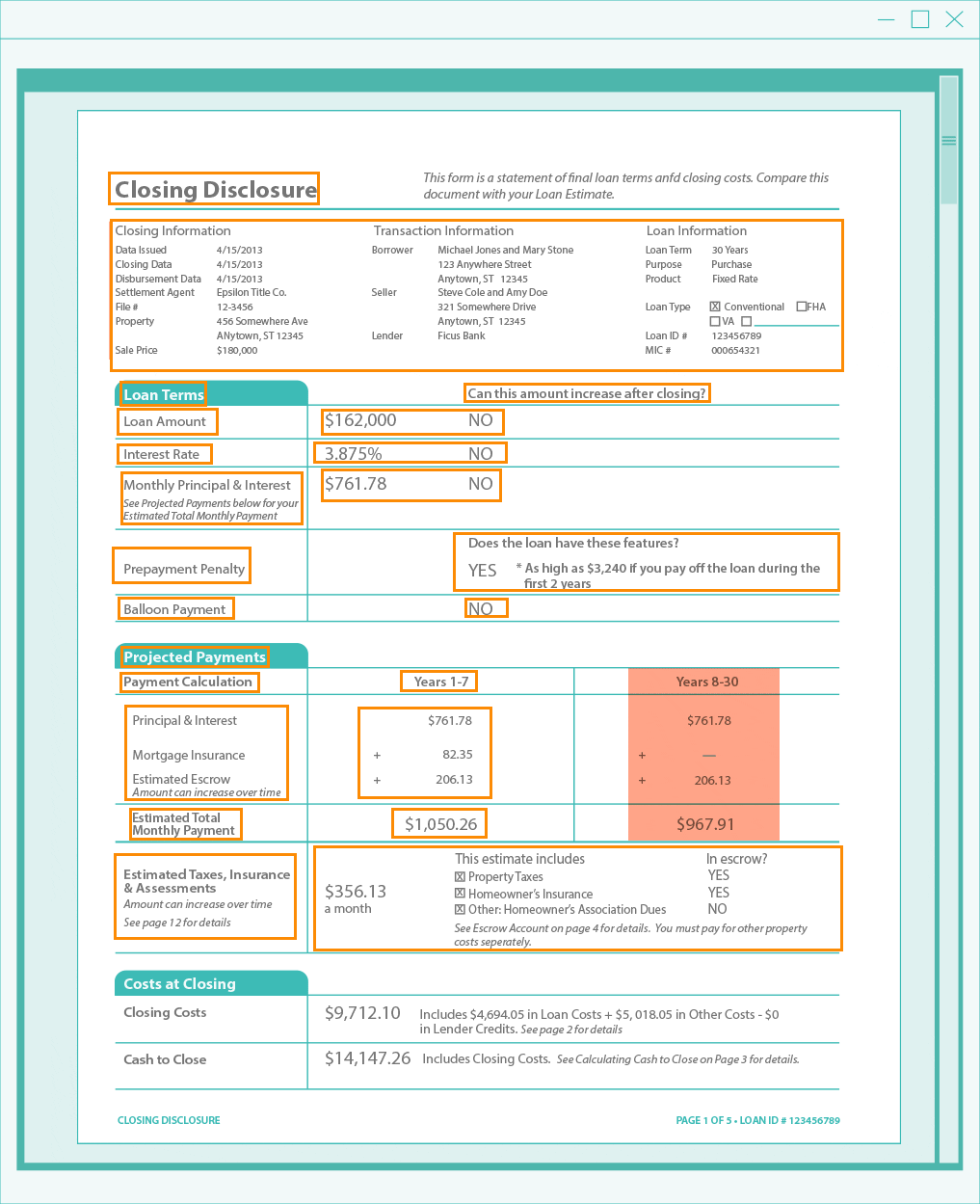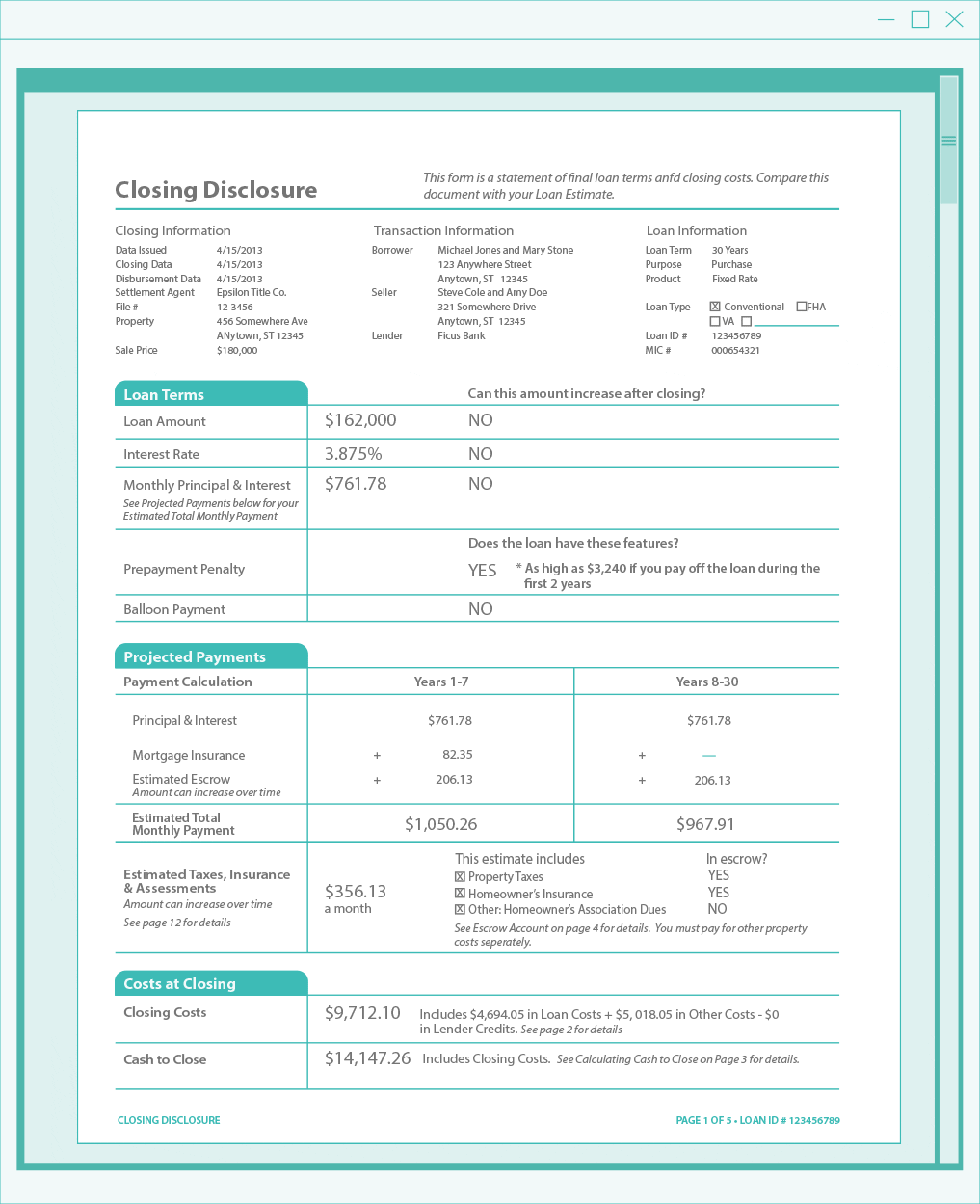 Here's what happens behind the scenes with the software: Essentially, it's looking for labels that we know are going to exist on the page.
Here's what happens behind the scenes with the software: Essentially, it's looking for labels that we know are going to exist on the page.
The software doesn’t need to know where they are going to be — only that they may exist — and if so find the relevant information. This is also how very complex medical forms are processed, such as:
Once the information you need to integrate or validate within your loan application system is found, it is put into a very easy-to-understand layout that mimics the document itself. And this is an important step — because no machine will read text perfectly.
Automated Mathematical and Error Validation is a Great Feature, Too
What a machine is good at, however, is knowing what data to expect:
- If math doesn’t add up, the software notices that there's an error and flags it
- If a character is read but the machine thinks it could be wrong, it flags it
Depending on the workflows you build, you will only present certain information to a human operator for review.
For instance, a loan file with 400 different document types is easily fully reviewed and the data is 100% validated within minutes (some claim within just 10 minutes).
This data — along with the actual document images themselves — is now ready to be integrated within other systems.
Factor 4: How is Extracted Information Integrated With Other Systems?
This is the fun part. Now that the servicing software has extracted accurate and validated information, it is easily moved into your loan origination, CRM, and/or content management system.
In one seamless process, you can
- Perform quick post-close audits
- Verify information with customers and
- Assure the quality of loan processing
On the back-end of the loan servicing software is the capability to connect with other systems through something called APIs, integrations through common file formats like CSV, JSON, or XML, or even direct integrations with other systems.
This software includes all the pre-built integrations needed to work with virtually any other software application you are running.
End-to-End Loan Servicing Made Easy
Finally, as you are evaluating solutions, pay close attention to the amount of effort and time required in each of these steps.
Your goal of fast and high-quality automation is easily within reach.



