
Optical Mark Recognition (OMR) is a technology that enables software to recognize marks made on paper documents, such as forms that contain checkmarks, bubbles, or boxes. Basically, OMR determines checkbox states and whether they are selected.
Companies use OMR to quickly and accurately extract information from documents with forms. If forms on a document are complicated or contain a lot of information (or if there are hundreds or thousands of documents), then OMR software can save significant time and money compared to manually entering this information in databases or downstream business systems.
Once a document is scanned, OMR looks for boxes and if there is a mark inside it. Some OMR software can also look around the box for a label and capture that information as well. The OMR method of collecting data is similar to OCR (optical character recognition) and ICR technologies (intelligent character recognition).

Most Common Applications of Optical Mark Recognition
 OMR can be used on any document that contains checkboxes, but it is really meant for documents that contain many checkboxes, bubbles, or mark boxes.
OMR can be used on any document that contains checkboxes, but it is really meant for documents that contain many checkboxes, bubbles, or mark boxes.
The most common applications for OMR include:
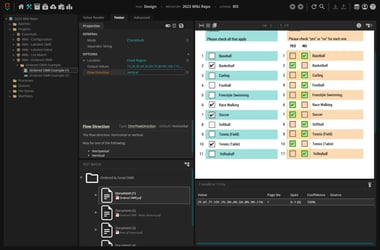
- Applications: We have many clients that use our OMR software frequently to capture checkbox data from many different kinds of government applications, new bank member applications, loan applications, job applications, etc. Above is an example of an application that is a great candidate for OMR software.
- Surveys, Assessments and Questionnaires: Many companies or government agencies use surveys to gather information from their customers or citizens. Many times these can still be in paper form.
- Medical Forms: The healthcare industry uses many complicated forms to get information from patients, from insurance forms to appointment applications, and treatment forms.
- Tests, Quizzes, and Exams: OMR can be used to capture "fill-in-the-bubble" data for multiple-choice questions used in colleges and high schools. Bubble forms and OMR can help teachers or administration grade papers quickly and accurately.
Advantages of OMR
 One of the many advantages of OMR software is significant time and cost savings. By automating what has traditionally been a process that relied on slow, painstaking manual data entry, thousands of hours can be saved every year. Optical Mark Recognition can process hundreds or thousands of documents per hour.
One of the many advantages of OMR software is significant time and cost savings. By automating what has traditionally been a process that relied on slow, painstaking manual data entry, thousands of hours can be saved every year. Optical Mark Recognition can process hundreds or thousands of documents per hour.
Those employees who performed data entry off OMR forms can simply be re-purposed for tasks that are far more valuable to the organization.
In addition to time and cost savings, OMR is also highly efficient and accurate. There are two reasons for this:
- Compared to manual data entry, intelligent document processing solutions don't make near the volume of errors that humans tend to make.
- There are many new methods that the best Optical Mark Recognition software use to get OMR data even more efficiently. One of those new methods is called 'Labeled OMR,' as it searches for labels around checkboxes in order to also capture the label information.
Get Our Free Video
on OMR Document Data!

Watch this video from our on-demand Grooper University to see how you can use Grooper's simple tools to find OMR data on your forms and documents and convert it into digital data!
Our OMR tools are second to none and can extract data from the most complicated documents. We can help you get data from forms that span multiple pages or are nested inside other tables. GET THE VIDEO:
Benefits of Optical Mark Recognition (OMR)
- Cost and Time Savings: OMR software automates the tough, plodding manual typing work from forms into data systems that humans have to do. A result of that is vast time and money savings.
- Accuracy: Intelligent document processing / OCR technology that employ OMR technology significantly cut down on the mistakes that humans commit in data collection. As the software is trained, it's accuracy increases further.
- Efficiency: High volumes (thousands) of documents can have their OMR data captured in minutes, compared to the weeks that a department of employees would need to finish the same task.
As the number of documents increase, and the number of OMR data fields (checkboxes or bubbles) increase, OMR software becomes even more efficient. - Multiple Uses: OMR software can be used on a wide variety of documents, such as: HR forms, healthcare forms, business applications, consumer surveys and even tests in schools. It can also be used in many industries like government, oil and gas, banking, and healthcare.
How Does Optical Mark Recognition (OMR) Work?
Actually, the basic idea behind OMR is very simple. Documents are scanned and the scanner shines a light onto the documents. Documents images are then recognized by the system:
- First, OMR looks for a box. The vast majority of OMR data is in checkboxes, so OMR software searches pages for boxes.
- In Grooper's OMR, a checkbox is simply defined as four lines connected to each other to form a square.
- In Grooper's OMR, a checkbox is simply defined as four lines connected to each other to form a square.
- After finding a box, OMR software examines to see if there are many black pixels inside the box.

- If an area inside the box reflects less light from the scanner than white areas, then the OMR software determines that there is a high threshold of black pixels in the box, the box is determined to be checked (or marked). If the box does not have a high threshold of black pixels, the OMR solution believes that the box is unchecked (or unmarked). The threshold is configurable, of course.
- Grooper's OMR detection then looks for labels near the boxes to extract the text of the field label and the checked label.
- In this example, the document is asking if someone is a United States citizen. The field label is 'U.S. Citizen,' and the text label that is marked is 'Yes.'

- In this example, the document is asking if someone is a United States citizen. The field label is 'U.S. Citizen,' and the text label that is marked is 'Yes.'
- If a label is checked or marked, then the label is returned as the result:
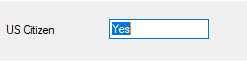 Other values can be returned instead of "Yes" or "No." Again, this is configurable. For instance, "US Citizen" or "Not a US Citizen" could be the return value.
Other values can be returned instead of "Yes" or "No." Again, this is configurable. For instance, "US Citizen" or "Not a US Citizen" could be the return value. - Once all of the data (OMR and OCR data) has been recognized and extracted, it can then be sent to databases, ERP systems, or other downstream business systems.

What Shapes Can OMR Software Detect?
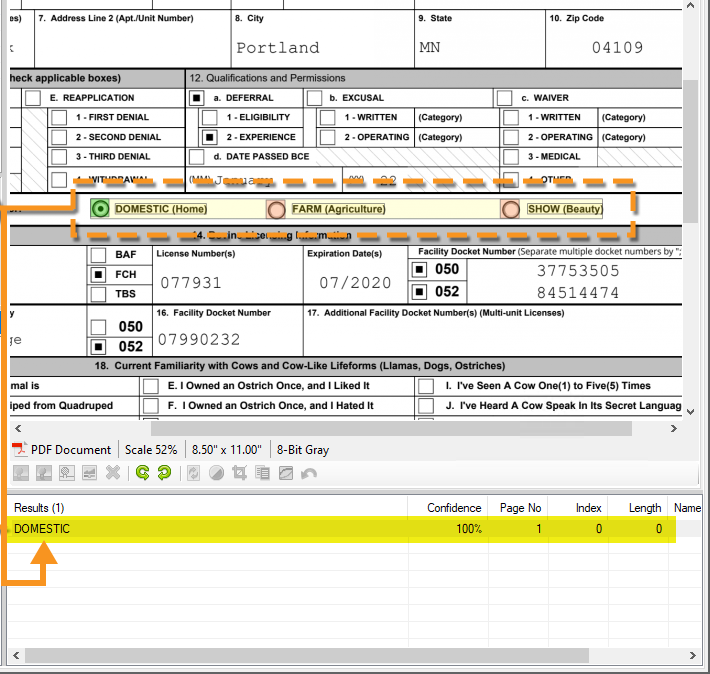
In addition to boxes, OMR systems can also recognize other shapes, like circles, which are sometimes known as 'radio buttons.'
The same steps are followed to detect whether radio buttons are selected. Here is an example in Grooper of OMR for radio buttons:
What's the Difference Between OMR and OCR?
These terms and technologies can be very confusing, as there is some overlap and similarity. But here is how OMR and OCR are different:
| OMR | OCR | |
| Definition | Digitizes all text off documents | Identifies marks on document forms |
| Pecking Order | A part of OCR | |
| Ease of Use | Easy | More Complicated |
| Applications | Wide variety of documents and structures | Only structured documents, like forms with checkboxes |
Definition
OCR stands for Optical Character Recognition. It digitizes text off plain paper documents so it can be searched or edited by other software applications. OCR converts typed or machine printed text from digital images of physical documents into machine-readable, encoded text.
The meaning of OMR is Optical Mark Recognition or Optical Marking Recognition. It is a technology that empowers other solutions (like OCR software) to identify marks on documents, like forms that have boxes, bubbles, or checkmarks on them. Put simply, OMR looks at checkboxes and whether they are selected.

Technology Pecking Order
This one is important to know: OMR is a subset of OCR technology. OMR is essentially a tool you can use within the OCR framework. OCR is not a part of OMR, but OMR is a part of OCR.
Ease of Use
In the past, OMR was tedious to set up and configure. Each box had to be drawn on the form definition. With the adoption of Computer Vision technologies, OMR can now be automatically configured.
This means that even complicated OMR sections can be quickly configured without the need to "draw boxes" for areas that contain OMR shapes. To configure OMR, just find the labels and set the values you want to be returned - it's that easy.
Applications / Use Cases
OMR has a narrow use case, and that is to target the information in documents with a lot of structure, like forms processing off scanned images. Or it can also be used to target just the highly structured portions of documents.
OMR can extract data off applications, surveys, healthcare documents, and government documents like tax forms or applications.
However, OCR is much more widely used and is leveraged to extract information from documents with various structures. OCR can extract data off forms, documents with paragraphs of text (like leases), or a mixture of structures, like invoices.



