
Integrating data for pipeline integrity management programs and MAOP verification is a challenging task.
With upcoming deadlines, and steep fines for non-compliance, operators are turning to artificial intelligence for help.
What is Pipeline Integrity?
Pipeline integrity is the concept of safeguarding pipelines and related components to ensure they are free from damage or defect, which prevents harmful chemicals from being released from the pipeline into the nearby environment.

Pipeline integrity involves all stages of the pipeline lifecycle, from:
- The beginning (drafting, design, and engineering)
- To commissioning, operation, inspection,
- To the end (repair, replacement or decommissioning)
The end goal of pipeline integrity management is that the pipeline system is safe, reliable and efficient.
For example, in the U.S., the Pipeline and Hazardous Materials Safety Administration provides rules for pipeline operators to comply with to prevent pipeline leaks or corrosion. Such rules stipulate that oil and gas companies routinely assess pipelines in regions that are at a higher risk of serious public or environmental safety.
Why is Technology Necessary for Pipeline Integrity Management?
There are over 300,000 miles of natural gas pipelines in the U.S. A significant portion of those were constructed prior to safety regulations mandated in the 1970's.
Much — if not all — of the information related to these pipeline systems is on paper.
 The alternative to processing paperwork with A.I. would be manually entering required pipeline attributes. With over 27 fields of data from numerous construction reports, this would be a tedious chore.
The alternative to processing paperwork with A.I. would be manually entering required pipeline attributes. With over 27 fields of data from numerous construction reports, this would be a tedious chore.
But more than that, if you've just acquired pipeline, you don't have the luxury of time to get all the information entered to ensure pipeline integrity.

THE BIG PROBLEM: Pipeline integrity management reporting must include all available information about the entire pipeline.
As a result, many different types of records in many different formats must be processed.
A.I.-based document processing is the only way to quickly and accurately process and integrate the diversity of pipeline information to meet the rigorous MAOP records verification process.
How AI Helps with Pipeline Integrity Management in 5 Steps
Pipeline integrity management is all about increasing safety with pipeline data.
For operators with historical pipeline documentation that hasn't been integrated into management systems, A.I. plays a crucial role in automating the process through 5 important steps:
Step 1: Making Text Machine-Readable
 Most pipeline system documents have been around for a long time, so they have their fair share of damage and blemishes. And some contain a large amount of hand printed text.
Most pipeline system documents have been around for a long time, so they have their fair share of damage and blemishes. And some contain a large amount of hand printed text.
To enable accurate optical character recognition (OCR) on documents, it is necessary to apply image processing to scanned documents.
The major obstacles to OCR are non-text artifacts such as:
- Speckles
- Hole punches
- Lines
- Pictures
- Warped document images
- And even handwriting
Using intelligent software, everything that isn't text is identified and removed prior to OCR. This ensures extremely high accuracy of text recognition.
Step 2: Machine Reading
Machine reading is a bit different than OCR. Traditional OCR "engines" process each pixel on a scanned page, and decide what character it represents.
This works OK, but accuracy is easily 50% or worse. It's difficult for OCR to know if a zero should be the letter 'O' or if the number one is really the letter 'l.' There are seemingly endless examples of this.
BIG TIP: Accurate pipeline data is a matter of human safety, so accuracy is vitally important.
 The difference in machine reading is that it uses intelligence, outside data sources (called lexicons), and multiple OCR engines to consistently extract data with over 90% accuracy.
The difference in machine reading is that it uses intelligence, outside data sources (called lexicons), and multiple OCR engines to consistently extract data with over 90% accuracy.
Machine reading engines break up text into logical groups. For design construction documents and blueprints where text is grouped into boxes or tables of information, machine reading will identify these groups and process them individually.
This is a major advancement that helps create machine understanding of what the group of data represents.
Step 3: Data Labeling
After accurate data is extracted from pipeline documents, it needs to be labeled. Simply turning a document of information into alphabet soup isn't very helpful.
Intelligent software looks at both the field labels on the document and the actual information itself to make judgement calls on what the data represents.
For example, you'll need to know the difference between pipe diameter and wall thickness or maximum allowable operating pressure and temperature. Because A.I. isn't perfect, accuracy thresholds are created to flag questionable results for human review.
In some cases, field labels on a document are either not available, or not very useful. In these cases, A.I. offers unique approaches like machine learning to label data based on surrounding data, or lexicons of information to compare data against.
Step 4: Transparency
Pipeline integrity management operators who trust A.I. need visibility into how results are obtained. Because intelligent software isn't perfect, it should offer a visual representation that explain results.
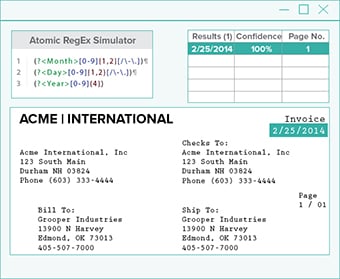 This ensures the system is adjusted for greater accuracy. Software that processes data without A.I. (or without transparency) is not robust enough to handle the diverse needs of oilfield data management.
This ensures the system is adjusted for greater accuracy. Software that processes data without A.I. (or without transparency) is not robust enough to handle the diverse needs of oilfield data management.
Transparency also includes providing a digital copy of the document that shows what pipeline data was extracted. This helps in cases where human review is necessary to verify a result.
Step 5: Data Integration
Not every operator works from the same information systems or has the same analytics tools. Data integration for pipeline integrity management is more than pushing data to a CSV file.
![]() Look for a tool that provides not just a data output file, but the ability to integrate according to existing master data models. This kind of tight integration attaches greater meaning to your data.
Look for a tool that provides not just a data output file, but the ability to integrate according to existing master data models. This kind of tight integration attaches greater meaning to your data.
Intelligent software that integrates data into virtually any pipeline data management application, or reporting application (even if it's an Excel spreadsheet) will help you maximize the use of data.
A Solution to Improved Pipeline Integrity Management
Pipeline regulations don't have to cut into productivity or profitability.
And since time isn't on your side, choose an intelligent digital oilfield platform to process pipeline system documents and automate pipeline integrity management, or even in buying and selling oil and gas leases.



